Taking a little bit of magic out of AI
Part One: Classifiers - it is easier than it seems

Context
Many people have argued that achieving AGI should not be possible with existing machine learning (ML) methods, mostly via philosophical arguments.
Yet undeterred the machine learning community has ploughed forward and used these methods to create some truly amazing applications. Accurate classifiers with thousands of categories that no purely human-written program can match, game players that can beat human world champions and downright charismatic LLMs.
All of these applications have a kind of magic to them. They provoke emotional reactions. Just like magic tricks, they often give people a sense that something that shouldn’t be possible is happening.
The point of this series of posts is to take a little bit of magic out of these applications. It is to add some context that makes them look a bit differently.
I plan to do one of these posts on classifiers, one on game players and one on LLMs. In doing so I hope to also explore what all of these tell us about classification, games and language and where they leave some of the old philosophical arguments.
This one is about classifiers.
Classifiers
In light of all the recent excitement, classifiers might seem boring. They don’t defeat you at chess. They don’t write a poem on command. They just sort out dog pictures from cat pictures. Yet I can still remember that something about them appeared quite magical when I first saw them.
If you try to write a computer program (say in C++) that would distinguish cats from dogs, it may seem like an impossible challenge. One might imagine that the algorithm would be looking for some kind of characteristic shapes. But which shapes and where? It seems hard to even specify what all cats have in common let alone what all images of cats do and then somehow recognise that. And one would then need to figure out the same thing for dogs as well.
Yet look at some of these classifiers created with ML methods. You show it an image of a cat and it says it’s a cat. You show it an image of a dog and it says it’s a dog. You show it a very different image of a cat and it also says it’s a cat. Magic.
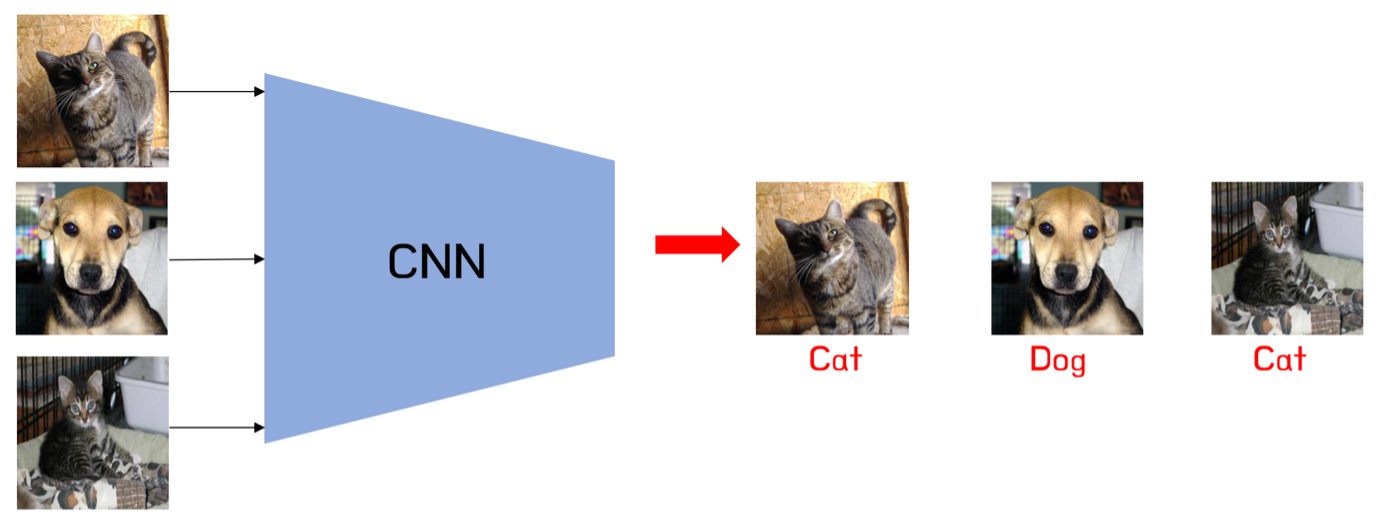
So how are we to explain the success of these ML methods? How do they allow us to create models, many of which consume no more memory than a typical C++ codebase, that accomplish something no human written codebase can match?
For that we first need to look at the classification task itself. What does it really take to solve it? To see the subtleties, consider two slightly different challenges:
1. Write a program that, when given an image, recognises cat images (returns “cat” when given one). For all other images it returns “other”.
2. Write a program that, when given an image, returns “cat” whenever given a cat image and “dog” whenever given a dog image1.
Superficially it might not be clear which of these two problems is harder.
It might even seem like problem 2 might be harder since the former asks us to recognise one category of things while the latter asks for two. Or it might seem like they are equally difficult since “other” seems to be merely a label just like “dog”.
But in reality, problem 2 is much easier than problem 1. This point is best visualised if we imagine all the dog and cat images being located in two blobs2 like this:
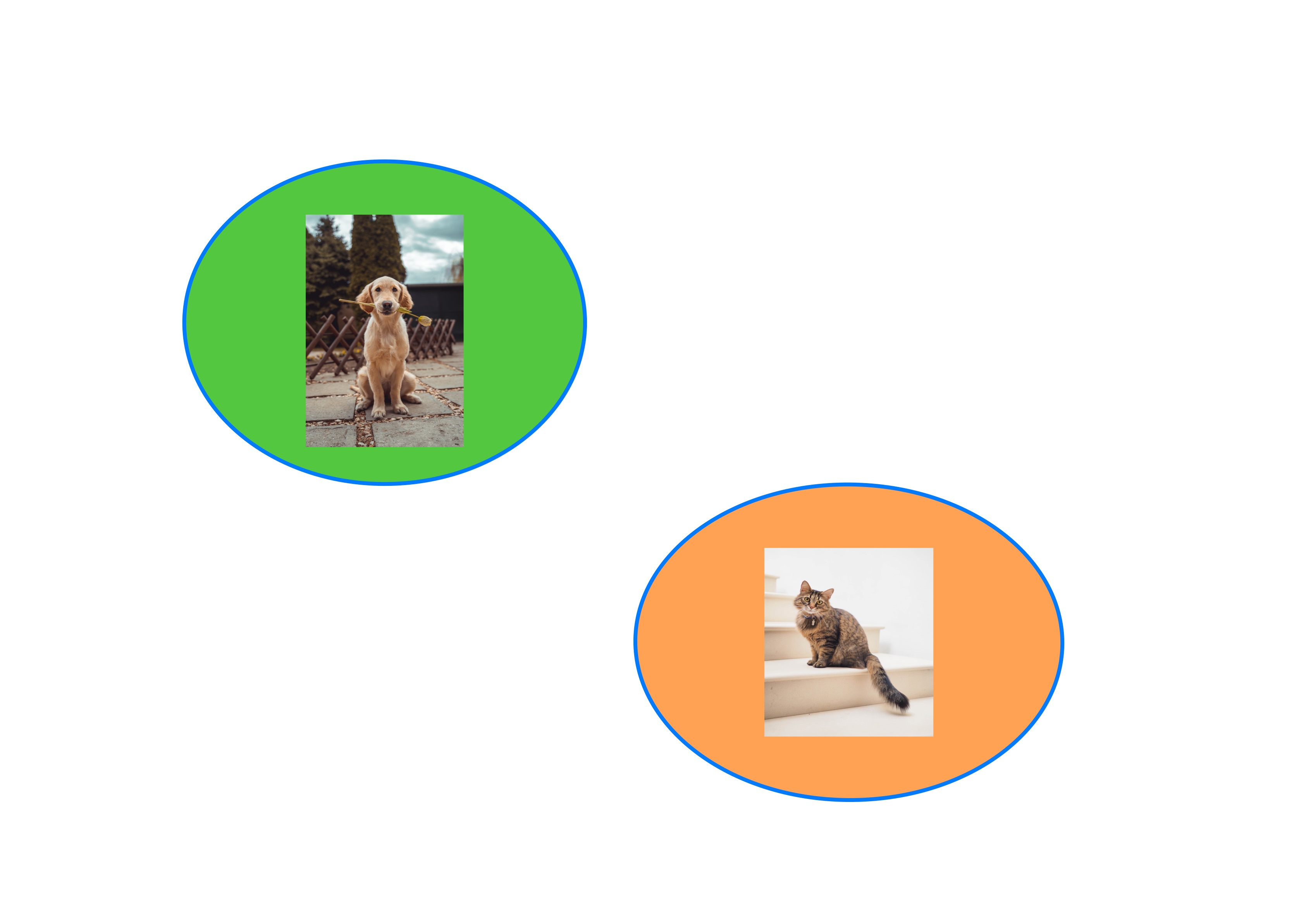
When presented with an image, the program will check whether it has some particular property and classify it accordingly.
To solve problem 1, we need to test for some kind of a property that only cats have. We need to find an essential cat property if you will. It needs to be a property only cat images have and images of dogs, skyscrapers and Mona Lisa don’t. If we were able to truly recognise cats in cat images, presumably we’d be able to solve this problem.
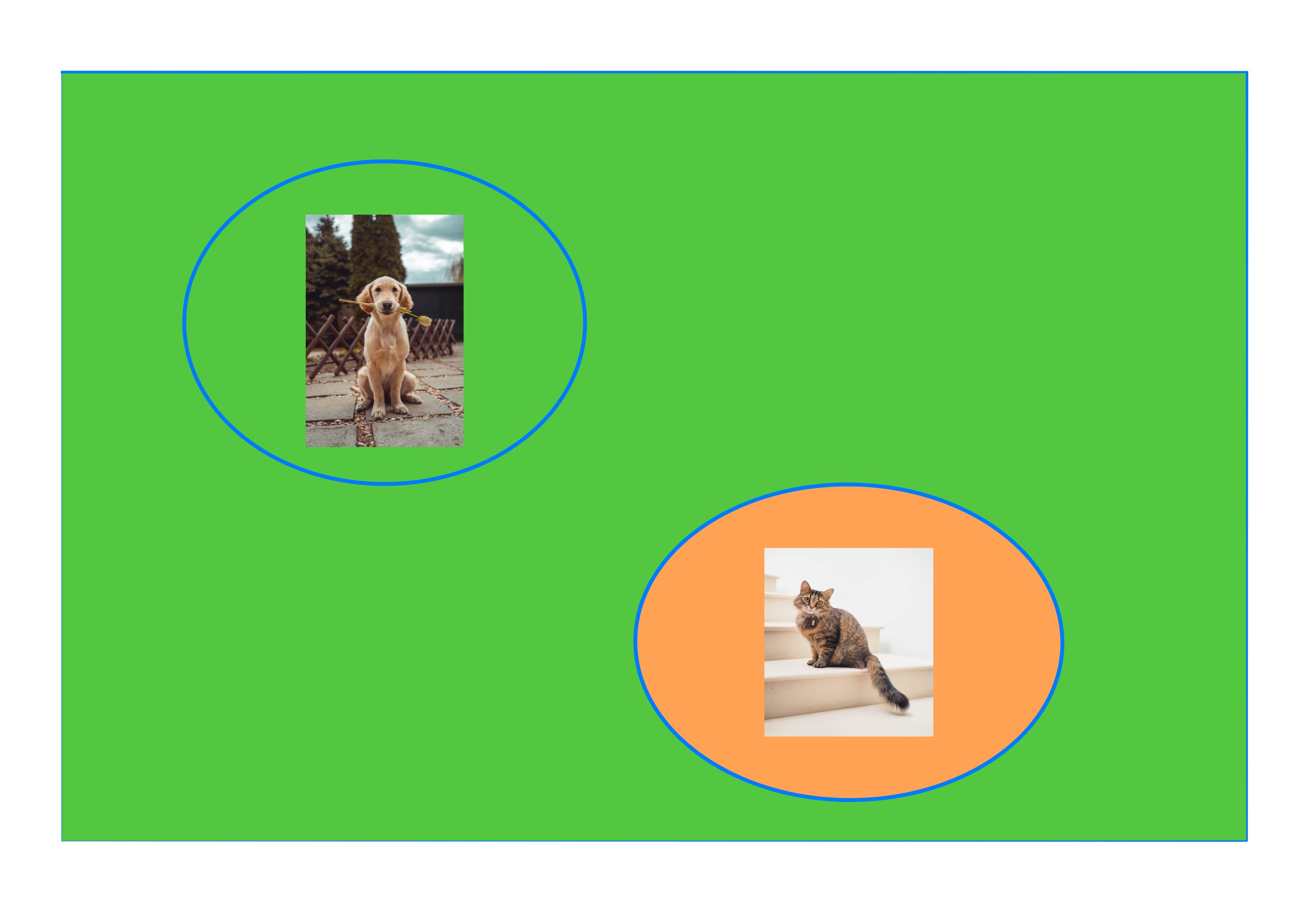
But to solve problem 2, we merely need a property that is correlated with cats, anti-correlated with dogs and can be arbitrary on all other images. There are many images other than cats that it can classify as cats. This un-restrictedness on other images3 – ironically images nobody cares about – is a part of what makes the problem considerably easier. And while being able to solve this problem doesn’t necessarily allow you to “see” or recognise anything in the image, it does allow you to solve the classification problem with high accuracy.



This is what often gets missed about classifiers. At first glance, it is often assumed that solving classification tasks requires us to somehow “see” objects in images – we need to detect cats in cat images, dogs in dog images, skyscrapers in skyscraper images. But in reality, we need far less – all it takes is finding properties that are strongly correlated with the various classes.
How do such properties look like? How much do they still have to do with the classes they are useful for classifying? Do they still have anything to do with dogs and cats?
There are plenty of such properties that have nothing to do with the classes being detected. One might think of them as correlated but non-essential properties. To see that this should be the case, just note their sheer diversity. All three partitions in the above images correspond to properties that would solve our classification problem, yet their mathematical descriptions all look vastly different and seemingly unrelated to each other.
Still, since it might be difficult to imagine what such properties are like, let’s look at one example that allows us to solve a simple classification task with 90% accuracy.
Example of simple, yet effective, non-essential correlated property
Consider another classic problem – classifying images of digits. To keep things simple let’s just try to distinguish images of “1” from images of “8”. How might we go about doing that?

If images of “1” and “8” in your dataset are approximately the same height and you think of “1” as being a straight line and “8” as two circles stacked on top of each other, then it’s not difficult to see you will use about 𝜋 times more ink to write an “8” than a “1”. The more ink (brightness) in the image, the more it makes sense to guess it is an “8” rather than a “1”.
If you have a large training set of images of “1” and “8”, you can use it to try to estimate the best critical ink amount – the point after which one will guess the given image is an ”8” rather than a “1”. And if you implement this, it gives you a reasonable classifier - when tested on the MNIST dataset, this idea gets to a classifier that is accurate about 90% of the time.
But one can see at once that there is nothing essential about being a “1” or an “8” that this property picks up on. It has nothing to do with “1”, “8” or their shapes. There are pictures of just about anything you can draw with one or the other quantity of ink. You could presumably use it to distinguish between many other pairs of classes. So, this property while useful for solving task 2 when it comes to images of “1” and “8” in a particular dataset is largely useless for recognising images of “1” outright.

As a general rule, when it comes to more varied and colourful pictures and categories, there will be patches with certain kinds of textures that will appear much more often in images from a certain category than in others. Consider for example these images of skyscrapers.

Almost all of them contain large patches containing the sky – and the sky has a characteristic texture without much additional structure. Images of cats almost never contain the sky nor sky-like areas. Hence testing for this kind of texture in an image is a reliable way of accurately distinguishing between images of skyscrapers and cats – in spite of what is being tested for not having anything to do with either.
There are many other types of correlated and inessential properties, but this should give a sense of how often images of certain kinds of objects become correlated with superficial features that have nothing to do with objects themselves.
What kinds of properties do ML methods find?
Still, one might wonder, do the best classifiers succeed by finding such properties or do they discover something more essential? Isn’t the idea they don’t contradicted by so called “semantic segmentation” of images that seemingly does outright recognise objects in a complicated image?

There are many pieces of evidence to suggest that they often don’t. These involve, for example, experiments where most of the properties of the object get destroyed while retaining the textures without ruining the classification.
In general, such non-essential superficial properties are often much simpler, robust and easier to test for than those that would require recognising some kind of finer structure in the image. Going back to the example from the previous section, testing whether the total brightness of an image exceeds a threshold is something that could be done with a single “neuron”. Much simpler than testing whether the image contains three separated regions of completely dark pixels, which would be another way of approaching the “1”/”8” classification.
But a really striking piece of evidence that these classifiers don’t discover the essential properties of the classes they classify is the existence of so called “adversarial examples” you can find in many machine learning models. Given an image from the training set it is often possible to find one that is imperceptibly different (to the human eye) from the original one, yet whose classification is different from the initial one. You can take a picture of cat, add the right set of imperceptible changes and its classification will sharply change. If the classifier was detecting essential cat properties, how could that be the case?4

Where do ML methods get an edge over humans?
But there is one further question that remains unanswered – even assuming the best classifiers succeed by checking for superficial properties, why are the methods used for producing classifiers so much more effective at finding such properties than we are? Why do they succeed where we fail?
There are two reasons for this which might be gleaned from the superficial properties described above. Both “total brightness” and “blue sky” are properties with a nice human-understandable description. But many properties you can implement in ML models simply don’t. Some of them correspond to nothing more than partitioning the space of images into a million different chunks and then assigning a class to each chunk in no discernible pattern. There is a large class of properties that is simply not accessible to us that these methods can examine.
Secondly, if given a candidate property, how do we know it’s a good one? In our examples, we had two nice stories about why a given property might be useful. But machine learning methods have something else – large amounts of data. Rather than having to come up with a story about why a given property might work they can statistically check whether it does. Furthermore, the data is also used to navigate the space of these inscrutable properties to the point where perhaps a better analogy for what is happening is that the method is really constructing a kind of a map of the space of all images with ever greater resolution as the amount of data and the size of the model increase (more on that in a future post).
But in short, the reason these methods get an edge is because they are working with a much larger space of properties than we are (many of which are inscrutable to us), have a reliable way of identifying good properties (testing them against data, whereas we’d have to come up with an explanation) and can also use it to navigate the space of these properties in search for a good one.
The comparison then is between a ship with a great navigation system versus a sailor who’s stuck on a few disconnected islands, not knowing how to swim.
There is a final question of why such properties exist, of why the search in the inscrutable property space often doesn’t come back empty handed, but that is beyond the scope of this post though I hope to say more about it in the future.
Classification in real life
If we now compare ourselves with the models rather than the methods, there is an additional question that could be raised: isn’t it the case that people also often make judgements on the basis of superficial and inessential signals? Are we really that different from these models? Isn’t all learning just picking up on correlations?
And to start with the first, it is true – people often make judgements and decisions based on superficial things like credentials, appearance and much else. The lesson of these models and their effectiveness is that we should be weary of interpreting whatever success we may have in doing so as being reflective of the signals we judge by signifying something especially deep or significant.
There really is such a thing as a skyscraper, not just the correlated sky above it, no matter how many images you classify correctly by ignoring that distinction. But given how big a role the focus on the superficial has had in human conflict, it does point to an important way in which we are different from these models.
Our unique human ability isn’t in picking up on subtle superficial correlations. It is in going beyond them by asking what the truth of the matter actually is and in moving closer to it by discarding existing categories and classifications. It is in our constant striving to go beyond appearances, our ability to connect with the world, to reconceptualise it – and to thereby discover it anew.
Thanks to Jasna Maver, Aleš Leonardis, Tomaž Leonardis, David Deutsch and Hana Skitek for reading and commenting on earlier drafts.
In the space of all images, there are images that are ambiguous between the two categories. There are images containing both dogs and cats. There are images of dogs made out of small images of cats. All sorts of other weirdness. For simplicity we are assuming all such images to be neither cat nor dog images, so that whatever the program does with them is acceptable.
Cat and dog images are not actually located in two separate blobs in the high dimensional image space. We draw them this way for simplicity – our main point about problems 1 and 2 is unaffected by this.
To be precise, even a property corresponding to a particular partition of the space will still have many different ways of expressing it.
In terms of explanation for the existence of adversarial examples, I was recently at the Heidelberg Laureate Forum where Adi Shamir gave a particularly illuminating talk about how they arise. It also contains many other examples of strange classification behaviour.
Nice post.
Did I understand you right that the basic reason they have an edge over a non ML way of programming (in these areas) is that they're programmed to be able to take many values of different properties and then permute them to find the one which best suits the task? Basically giving them the ingredients and telling them vary these to find the recipe?